
Attention机制_transformer
self-Attention
用Q来找相关的K
计算新的具有注意力信息词汇的过程
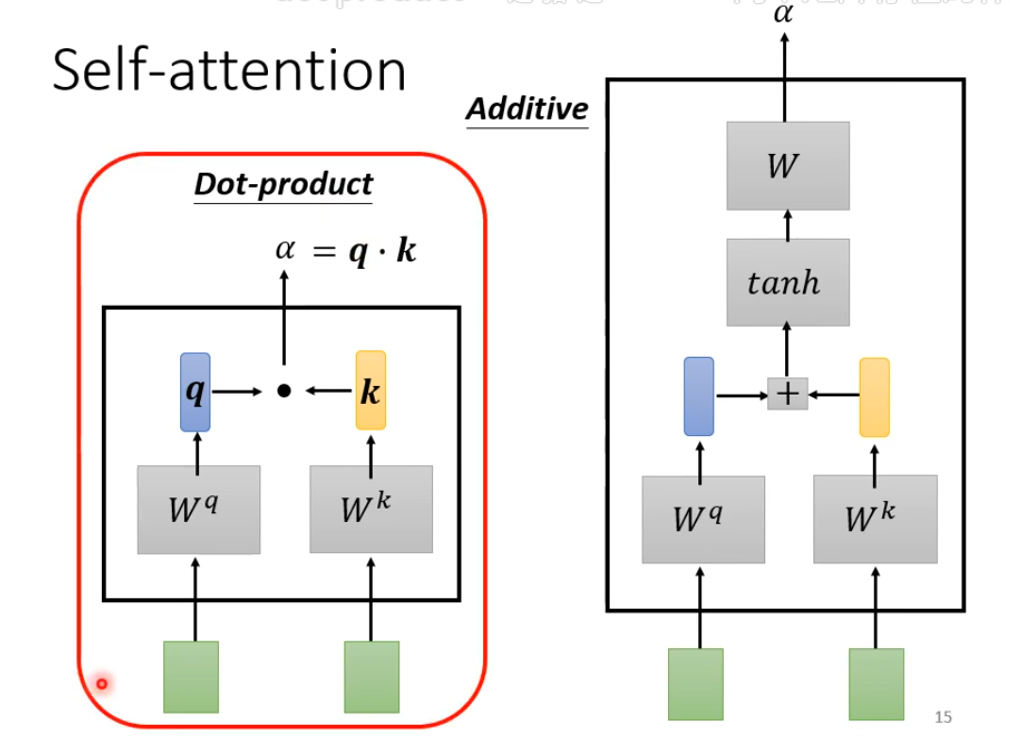
self att的 两种不同的架构
这是计算两个word的注意力分数,矩阵为一个transformer
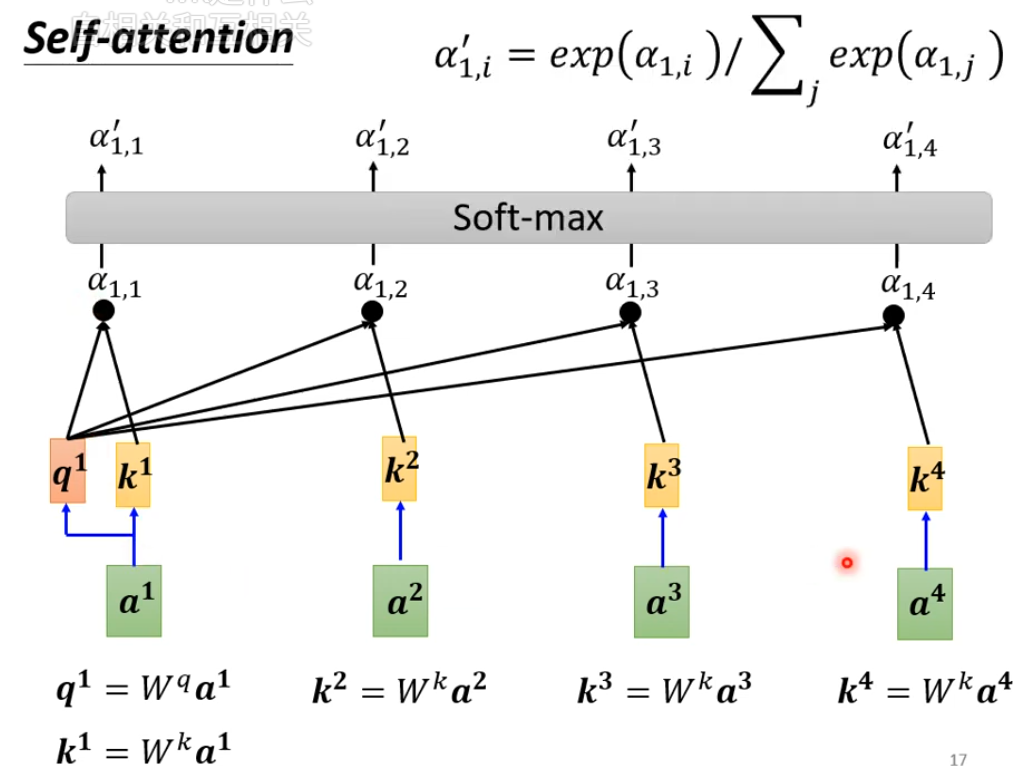
第一个词分别和其它所有词做注意力分数计算(包括自己),最后把分数进行softmax得到最终分数
相当于查询矩阵, 相当与键值矩阵, 相当于获取原始值矩阵。这三个矩阵都是共用的,这三个矩阵来控制这几个词的互相的注意力大小
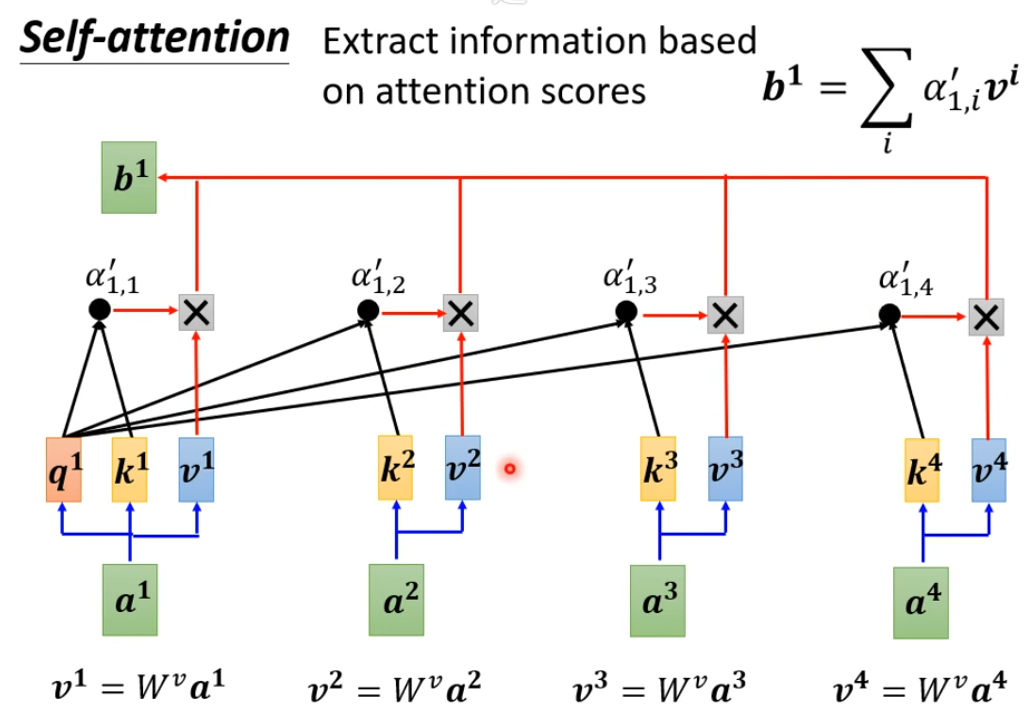
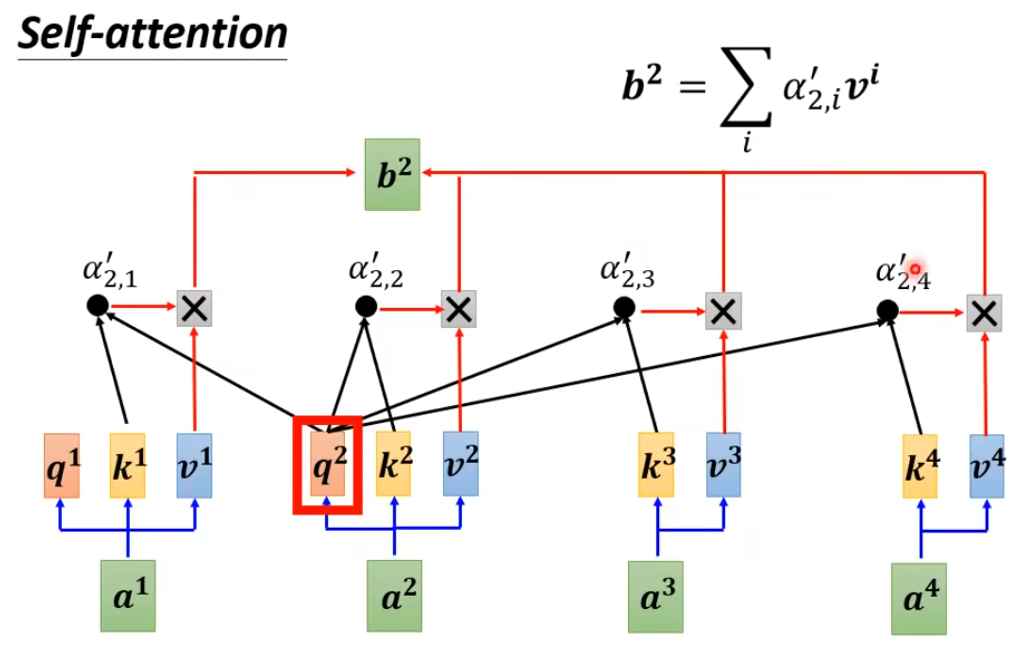
每个词用获取自己的向量,获取被查询词的向量,两向量进行点乘–> softmax后得到相似度(注意力)分数。最后这个查询的词利用获取到的所有与其他词的注意力分数和获取的原始值分别相乘后相加得到一个新的向量。
这个词的新向量就包含了其它所有词的联系信息,并且联系强弱不同,即所谓的自注意力。
计算过程
计算过程
矩阵乘法角度
既然 都是共享的,那么计算 就可以用矩阵乘法来一次性并行计算出来
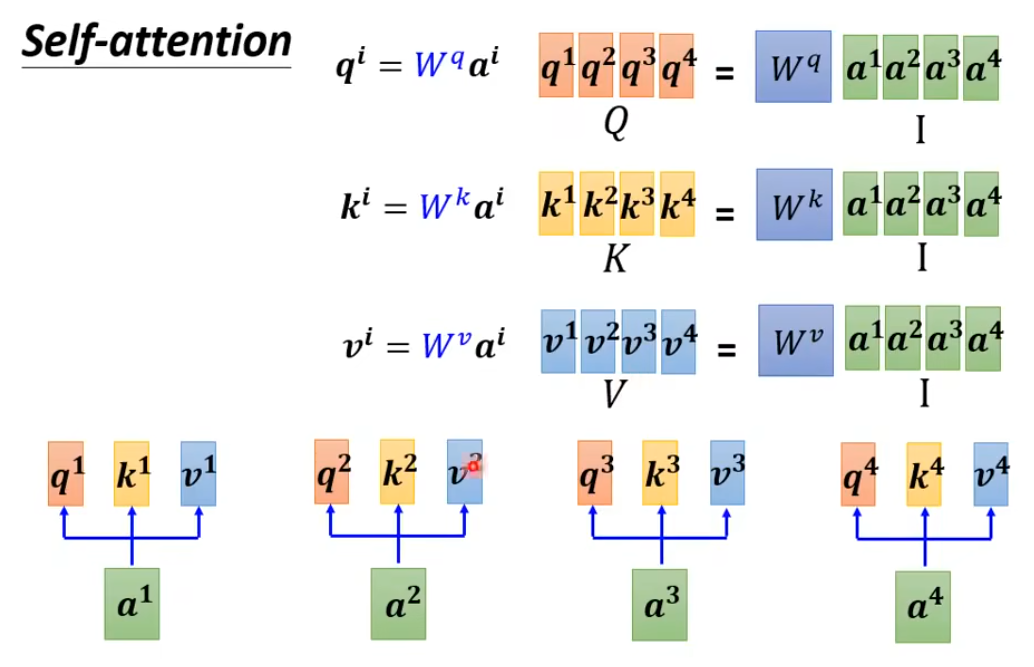
1. 计算
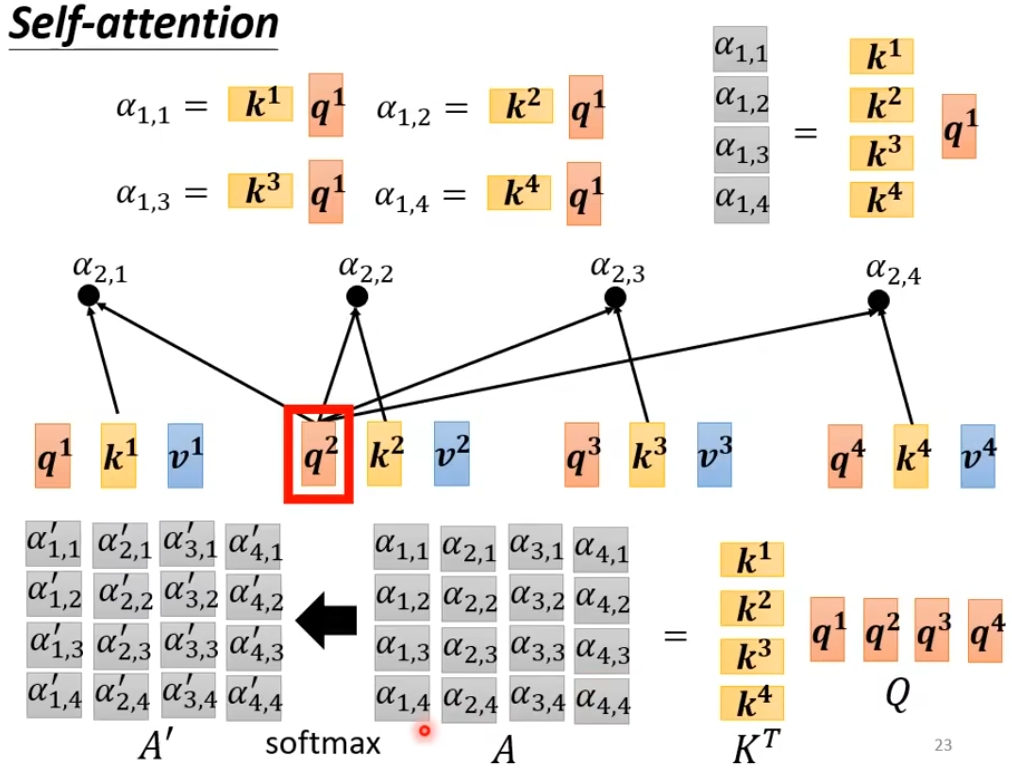
2. 计算注意力分数
每个词汇的q,分别乘其他矩阵的k,来得到与其他词的注意力分数
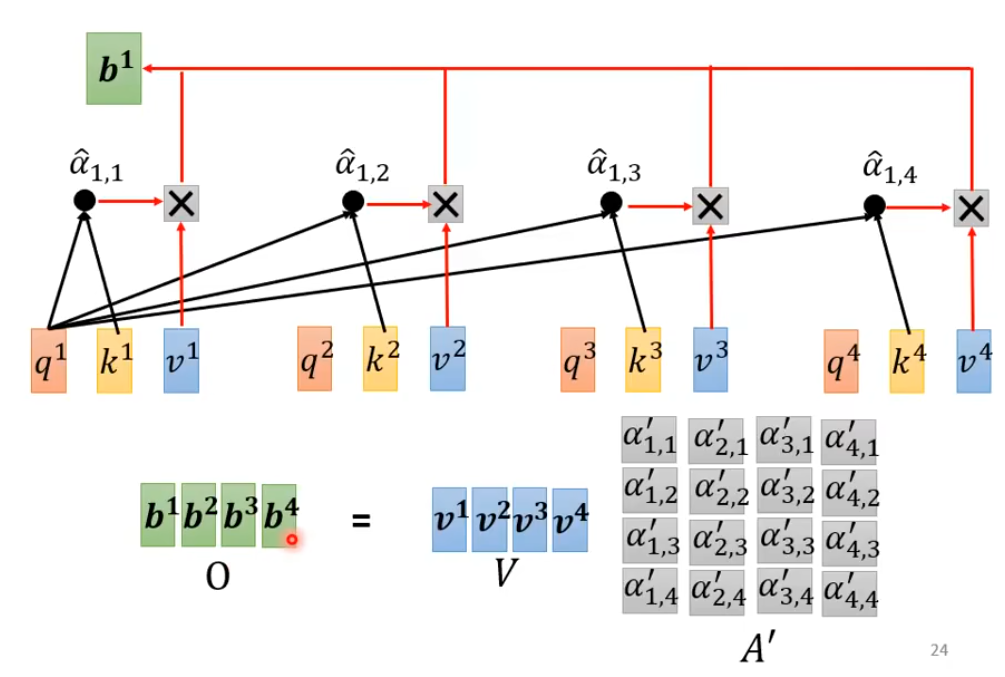
3. 计算新的包含注意力信息的词汇
注意力分数和原始词汇通过 transformer后相乘得到最终的新词汇
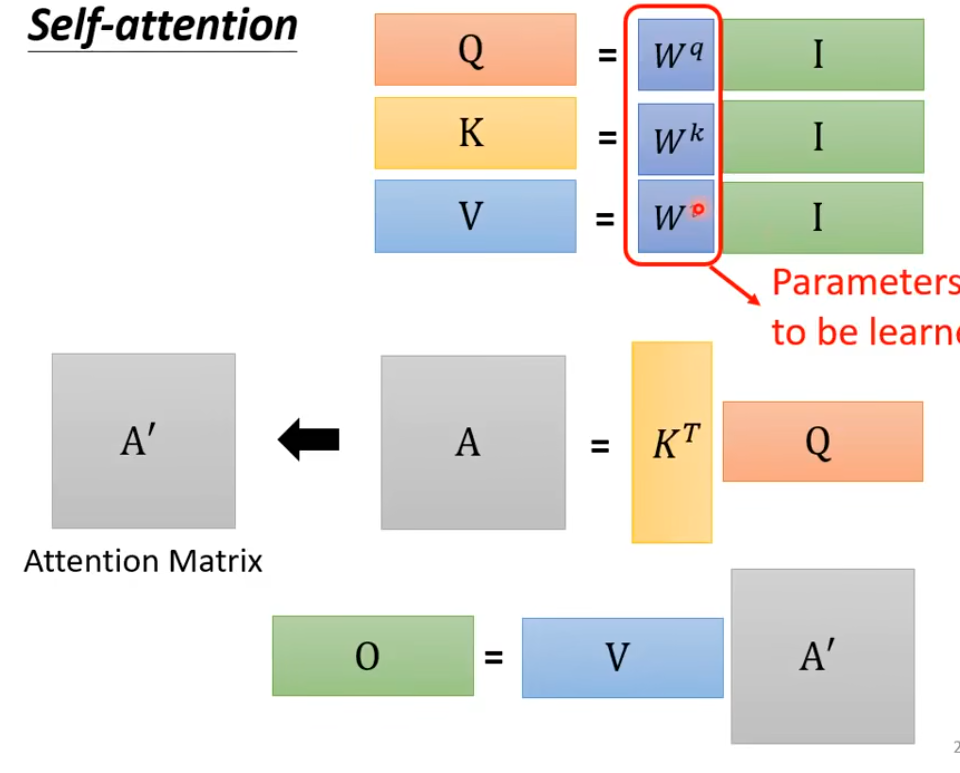
4. 总过程
只有 是需要学习的,这三个控制所有的相互之间的注意力大小
Multi-head Self-attention
自注意力就是用Q来找相关的K,但是“相关”会有很多种不同的种类不同的形式,所以需要多个Q来找不同形式的相关。
计算b1的不同形式的注意力结果
与一起算,与一起算
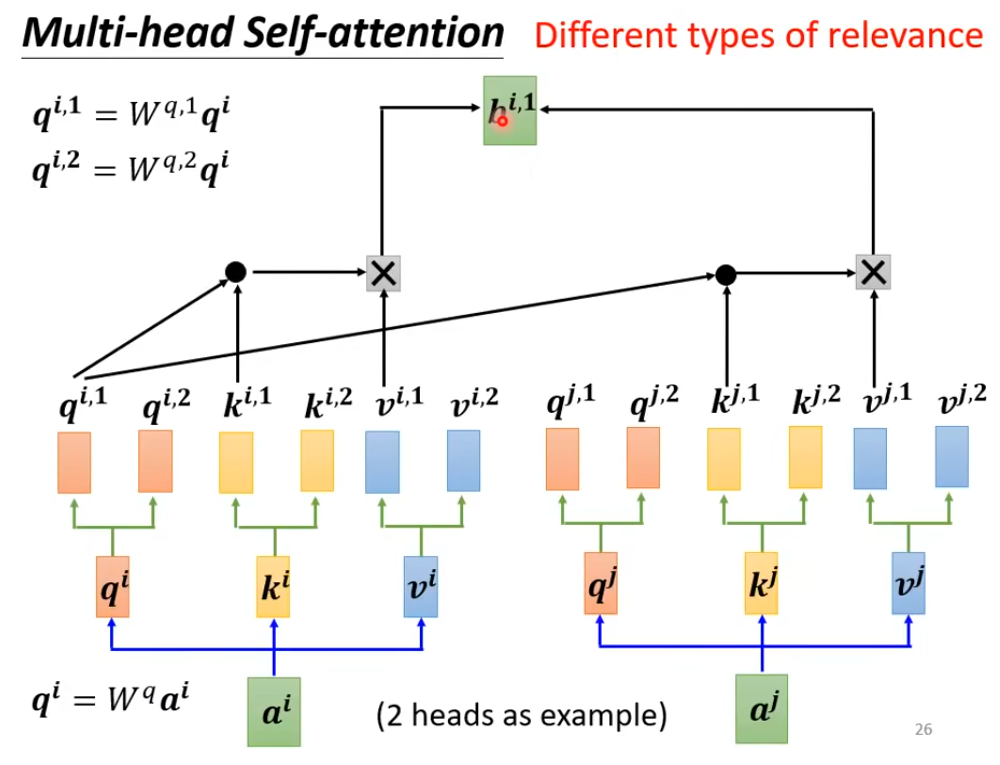
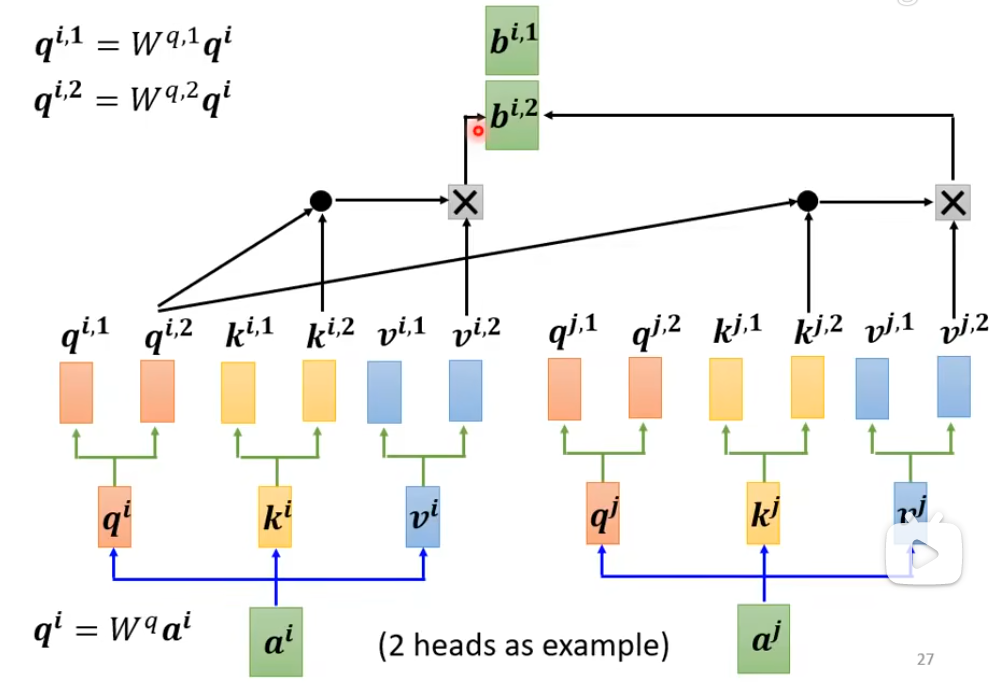
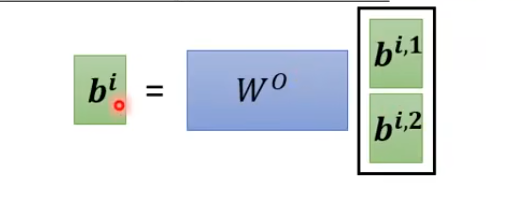
最后把这个词的不同形式注意力结果拼接起来乘上最终的一个transformer 得到这个词汇的最终注意力结果
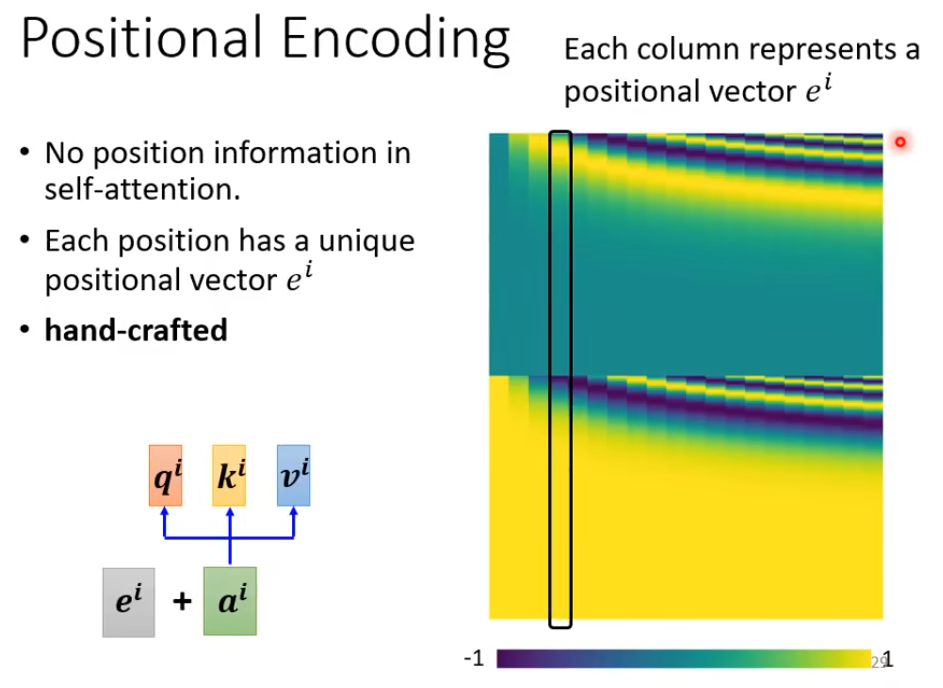
Positional Encoding
以上说的self attention虽然包含了其他词汇的注意力信息,但是少了个非常重要的信息–位置信息。 比如“saw a saw”这个句子中两个“saw”谁前谁后 前面提到的self attention并不知道。
不同的位置都有一个位置vector
self-Attention 在图像领域应用
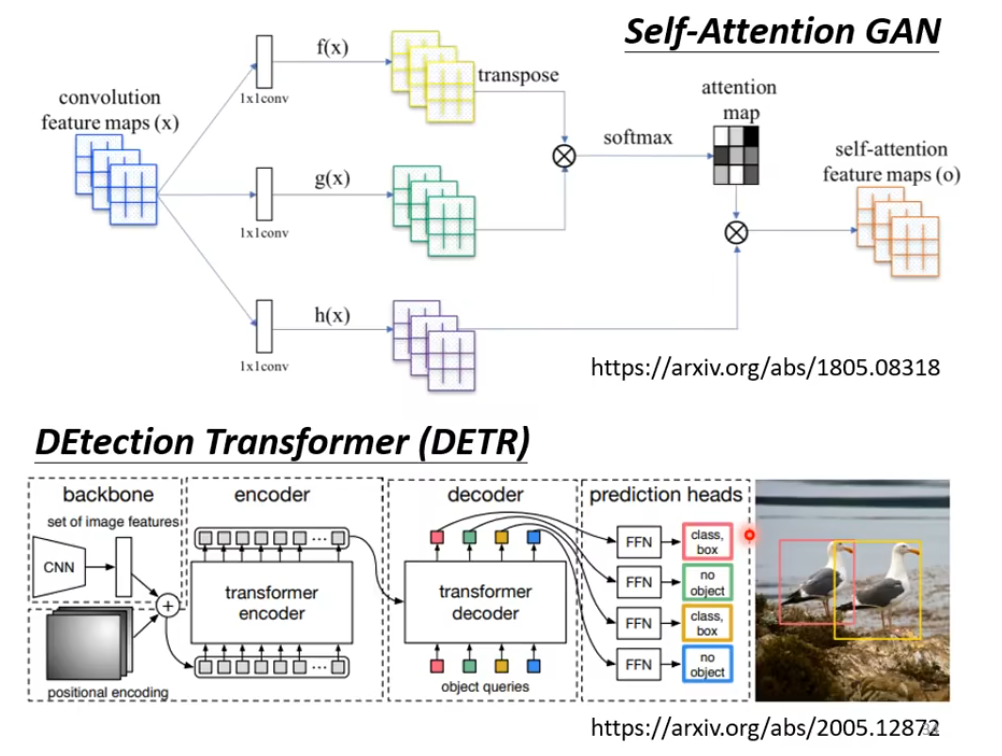
f(x),g(x),h(x)就是 QKV
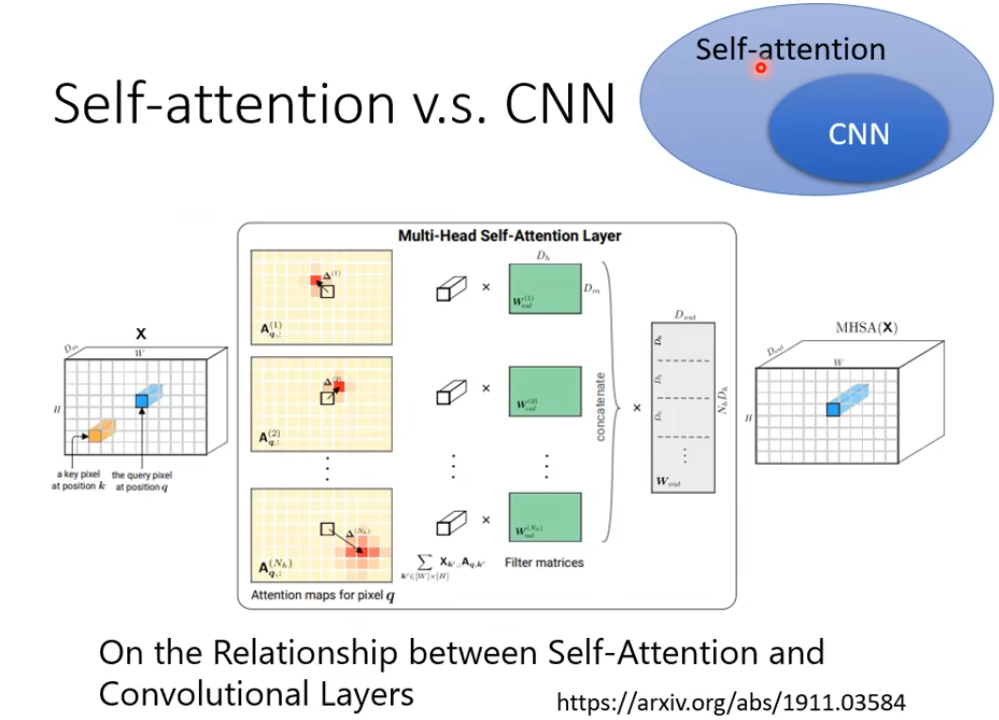
1. 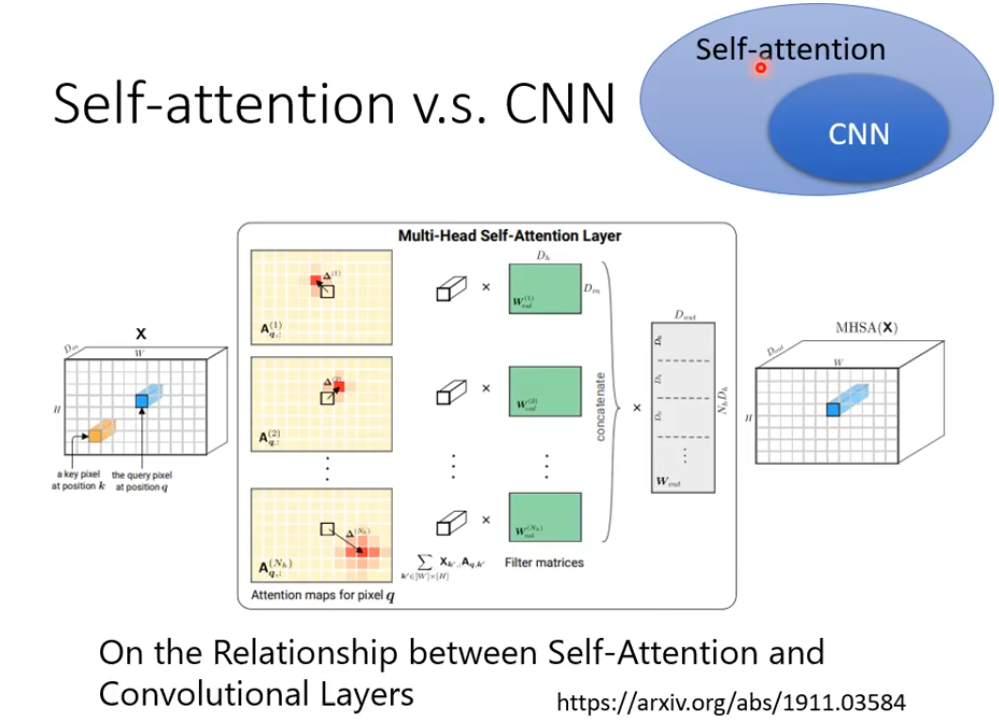 Self-Attention VS CNN
Self-Attention VS CNN
如果把图片做inner poduct的时候,如下图 A处的像素做Query,B处的像素做Key,每个像素考虑的就不是和CNN一样在卷积核的小范围内了,而是考虑的全局信息,所以CNN可以说是一个self-ATT的简化版本。
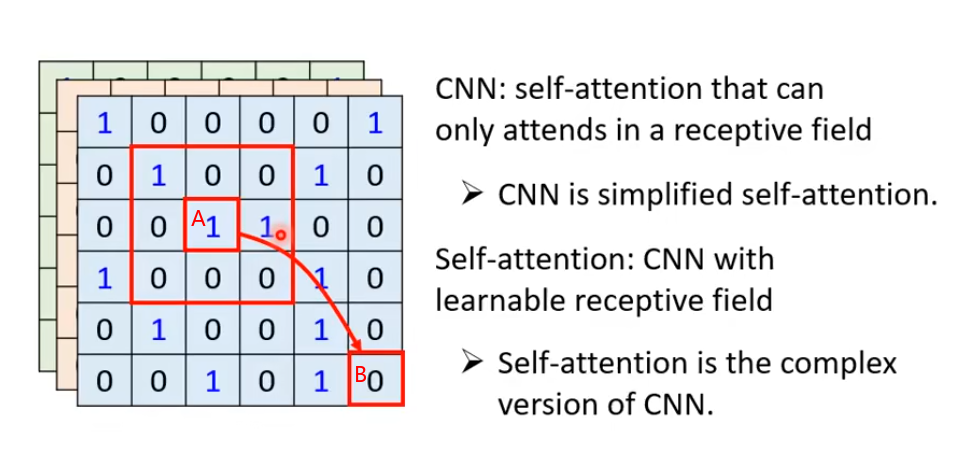
CNN的receptive field是认为划定的,而self-ATT的receptive field是自动学习出来的。
下面的论文用数学的方式证明CNN就是self-attention的子集。
CNN适用于数据集少的情况,不容易过拟合
2. Self-Attention VS RNN
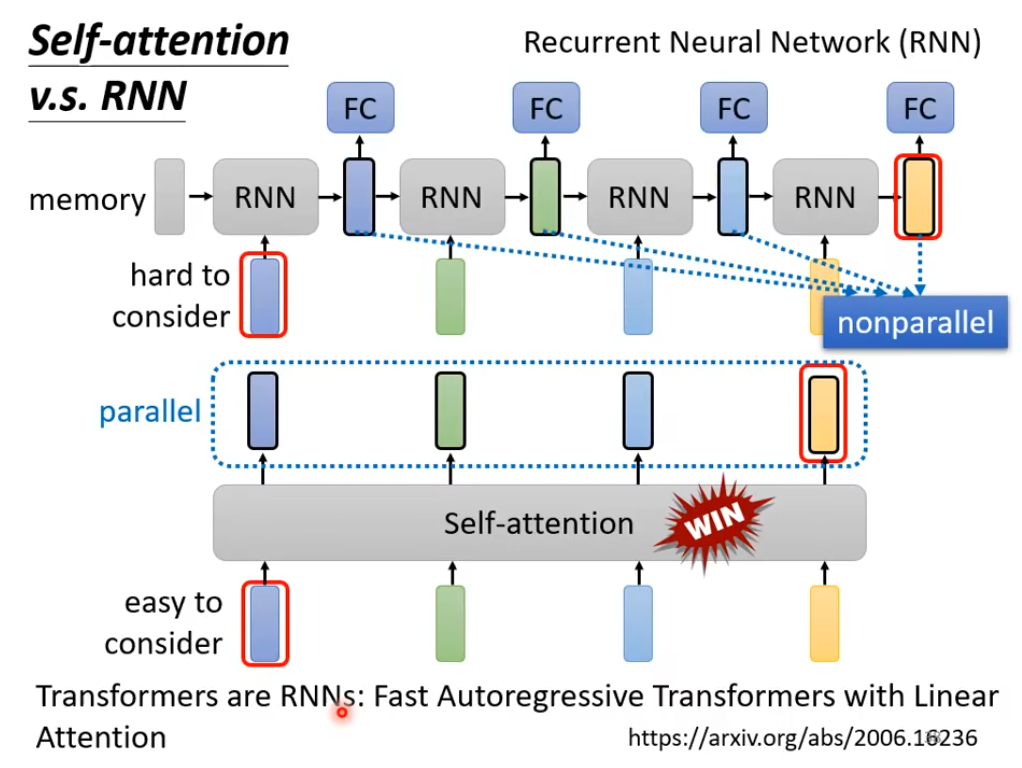
关键的区别就是RNN的词汇要和离着非常远的词汇建立联系的话,会存在梯度消失的现象,难以训练,而Self-Attention不存在这样的问题
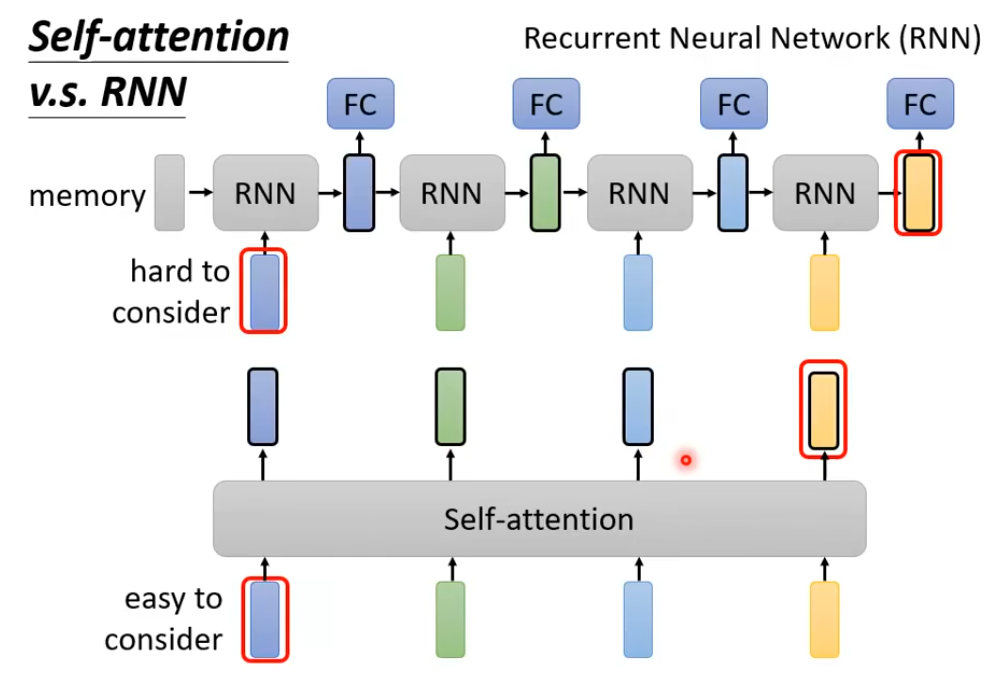
而且RNN无法并行处理所有数据
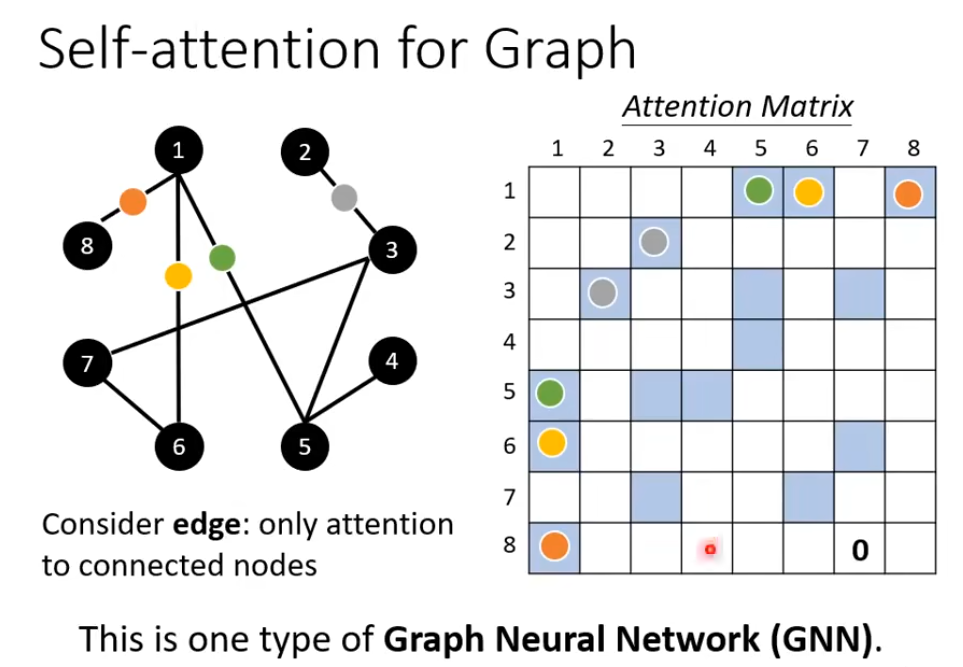
3. Self-Attention for graph
在之前的网络中,每个词汇之间有没有关联是自己学习出来的,但是在图里面,点之间的关联信息已经给出了,只需要计算有关联的点之间的注意力分数就够了。
Transformer
https://www.bilibili.com/video/BV1Xp4y1b7ih?p=3&vd_source=a61337b33cfc68a14ecb4713a0602ea5
transformer 是个seq2seq的model
seq2seq有几种情况,一对一、多对一、多对多、输出长度不固定 需要网络自己学习,例如语音识别和翻译
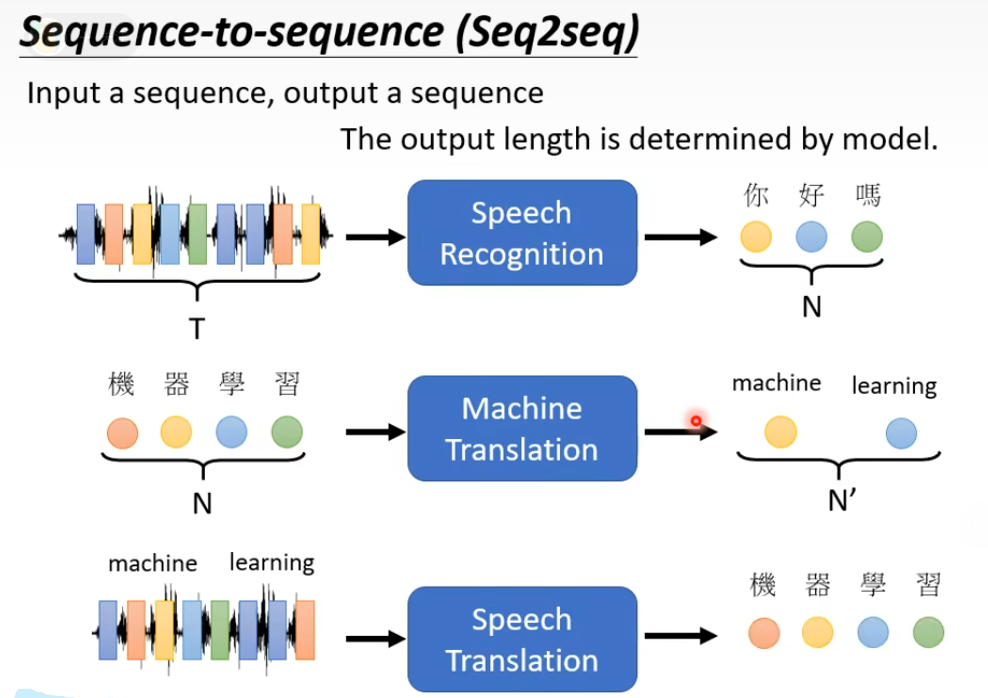
输入长度和输出长度之间的关系不是固定的
1. transformer架构
有一个编码架构,有个解码架构
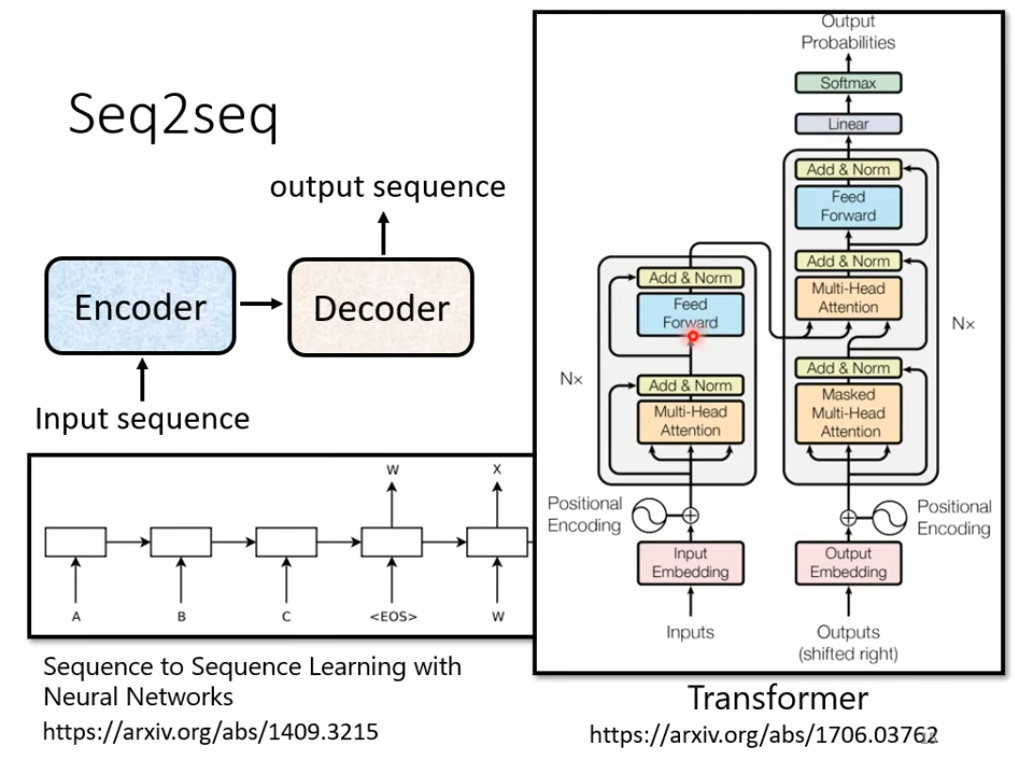
2. Encoer部分
作用就是给一排向量 ,输出另一排向量(包含注意力信息)。可以用CNN、RNN、Self-Attention做,Transformer里面用的是Self-Attention
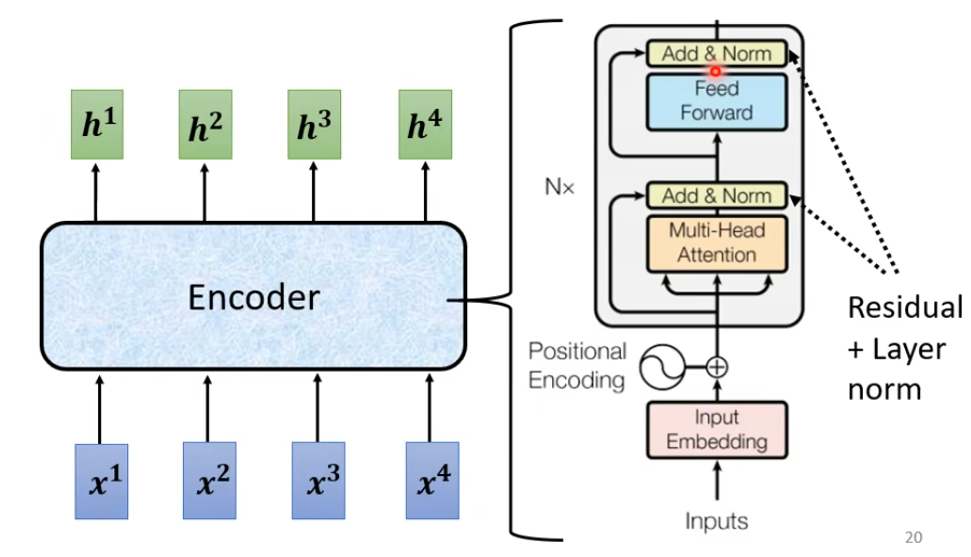
每个Encoder里面都有很多 block(对应上图中的Nx块)
每个block都是先经过Self-Attention(对应Multi-Head Attention)然后再FC(对应 Feed Forward)
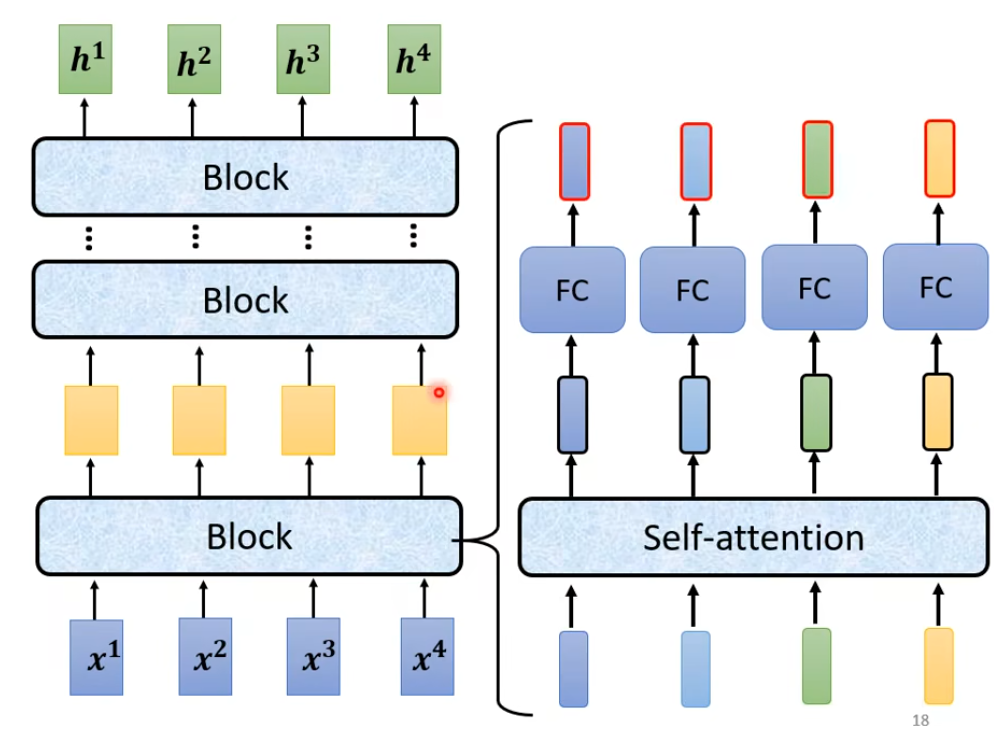
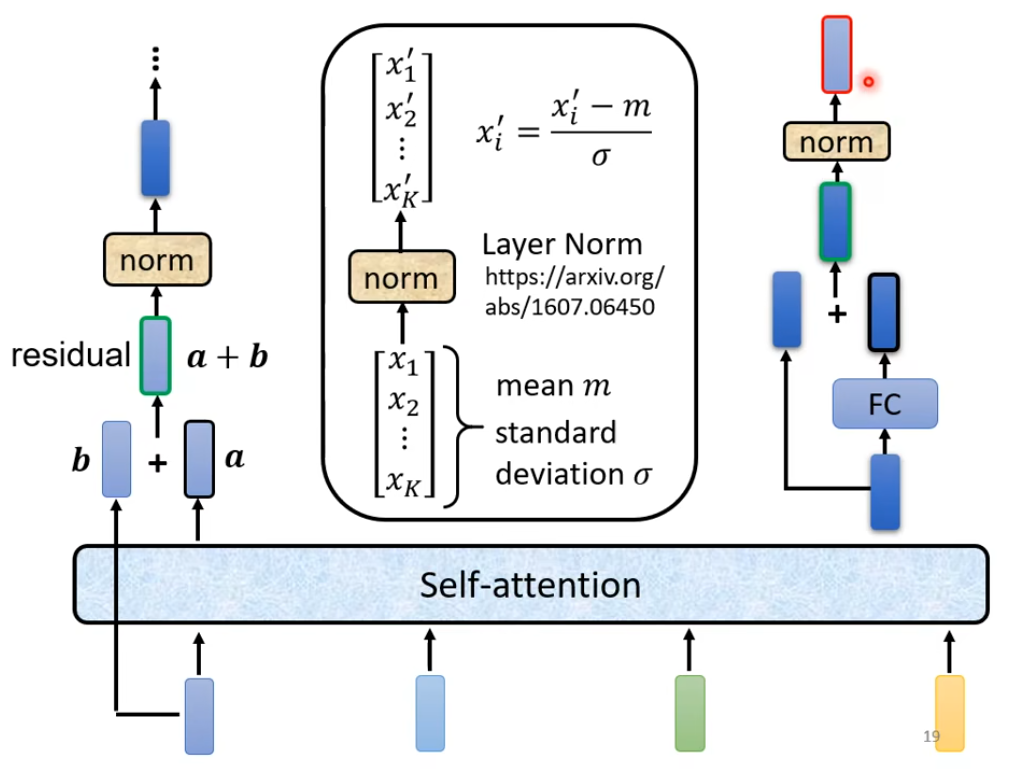
在block里面还加入了残差的思想:经过self-Att 和FC 后先和原输入残差连接(对应Add),然后在进行Layer Normal(对应Norm)
注意这里的normal是layer normal 不是 batch nomral
To learn more
以上是原论文中用到的结构,也有很多改进版本:
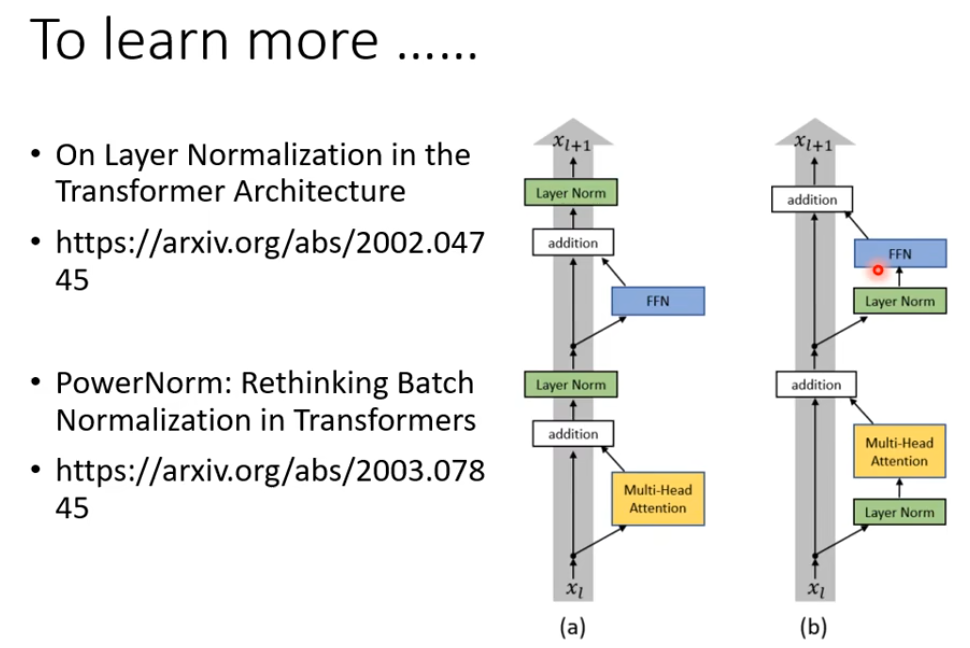
第一篇文章讨论了layer Norm的位置在哪更合适
第二篇文章讨论了什么Normalization更好
3. Decoder
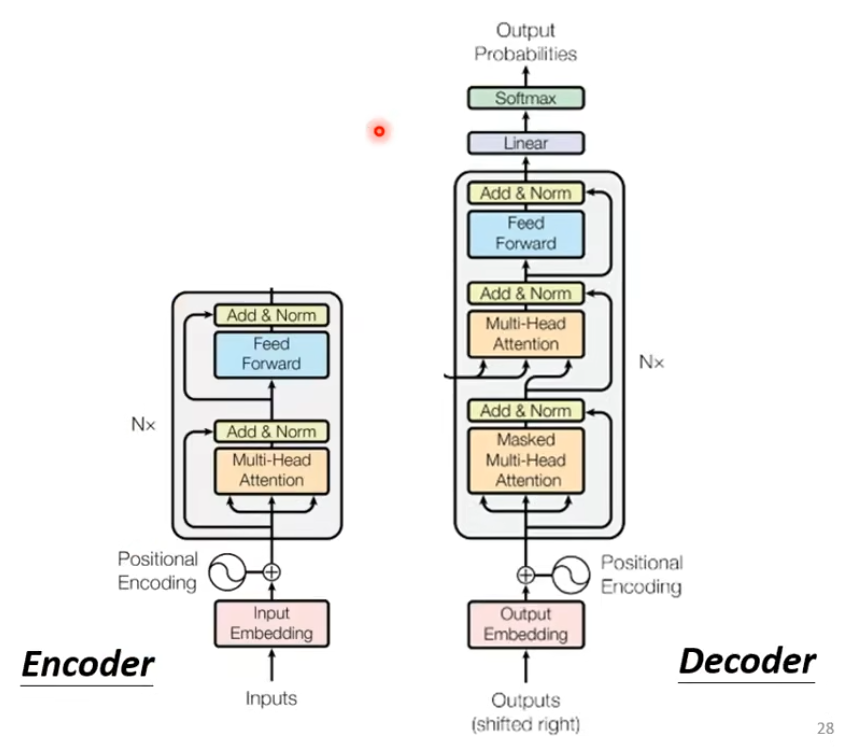
Autoregressive
依次产生每个词
整体过程
在Decoder中,首先把Encoder的输出先读入(具体怎么读入的先不展开)
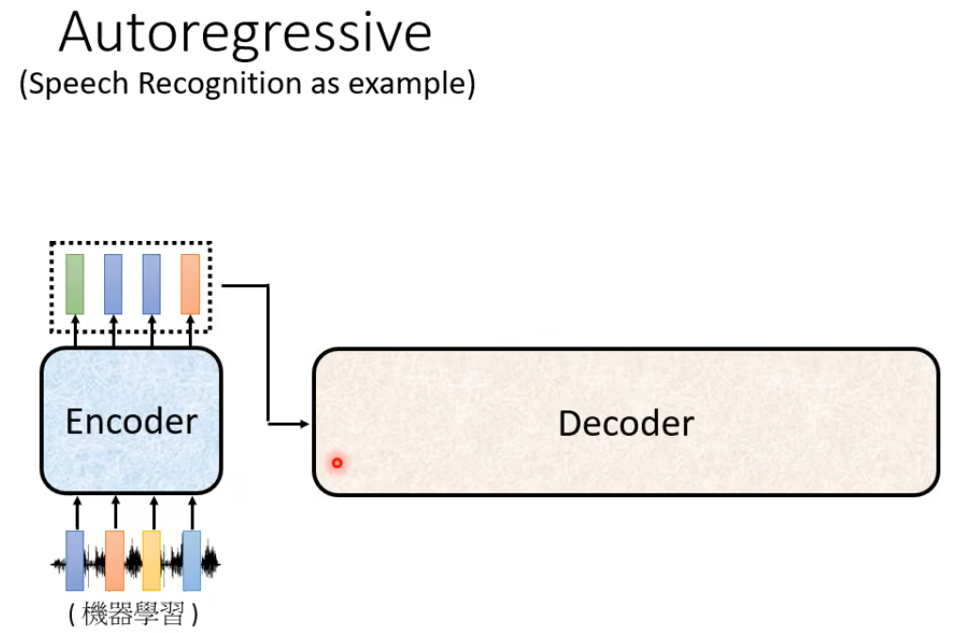
首先定义两个特殊的符号BOS(Begin of Sentence)、EOS(End of Sentence)
Decoder类似于RNN,先根据输入生成第一个词汇
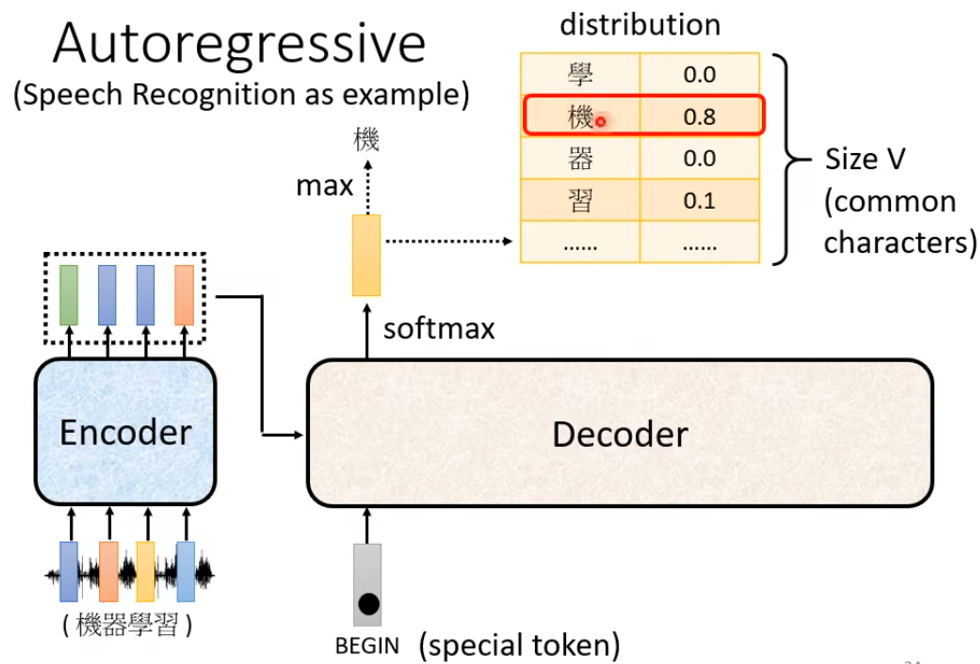
然后将这个词汇作为下一步的输入 … …
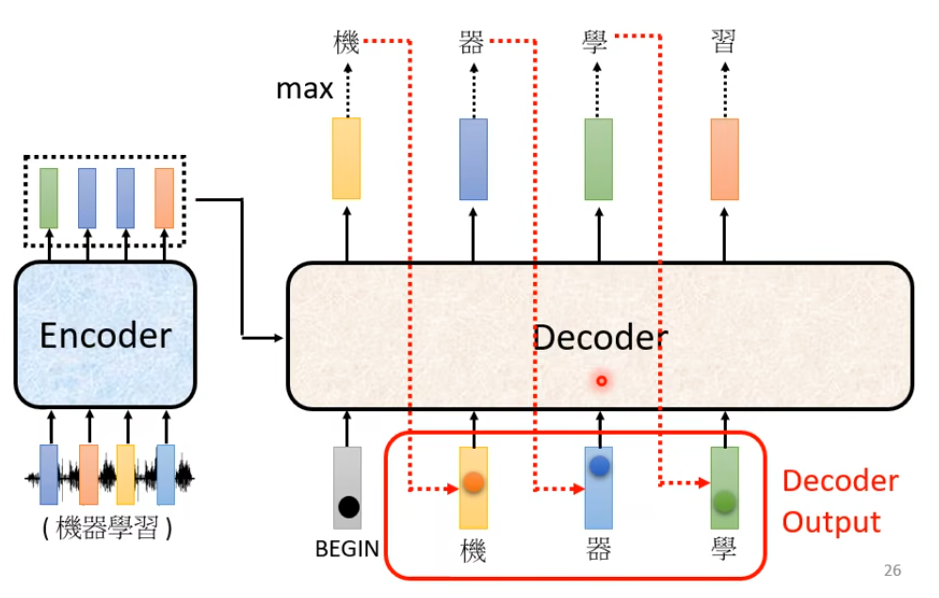
这里存在一个问题就是会存在错误传播的问题,即一步错,步步错
详细结构
如果把Decoder中间这部分遮住,则Encoder、Decoder两个差不多
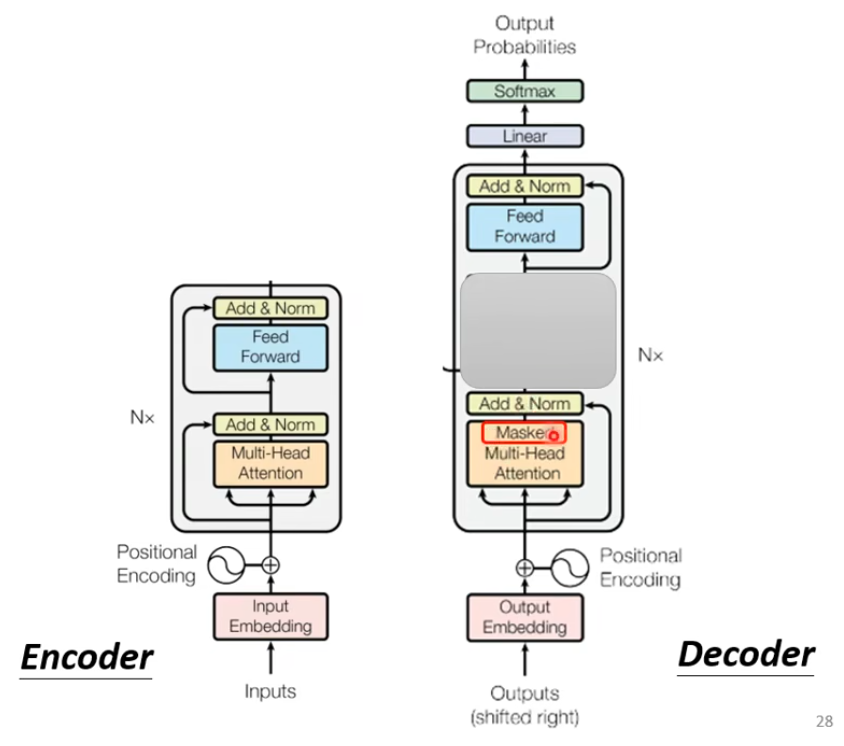
Masked Self-Attention
区别在Decoder中有个Masked,那这个Masked是什么意思呢:
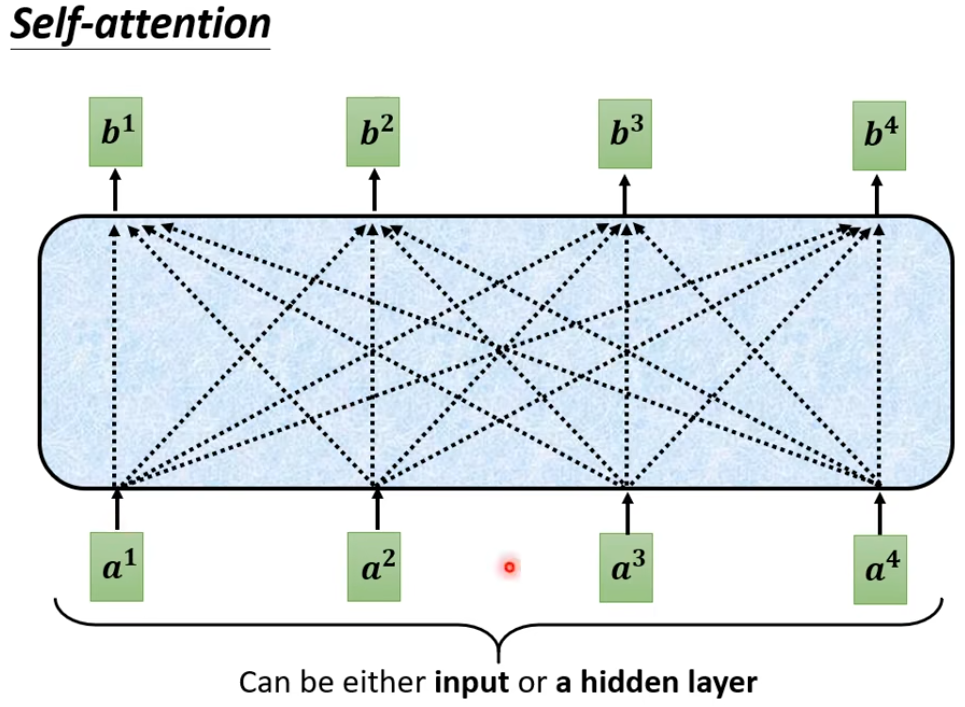
在原始的Self-Att中,每一步的输入都会考虑到后面所有步的输入
在Masked Self-attention中,当前词汇的产生不能考虑后面的部分
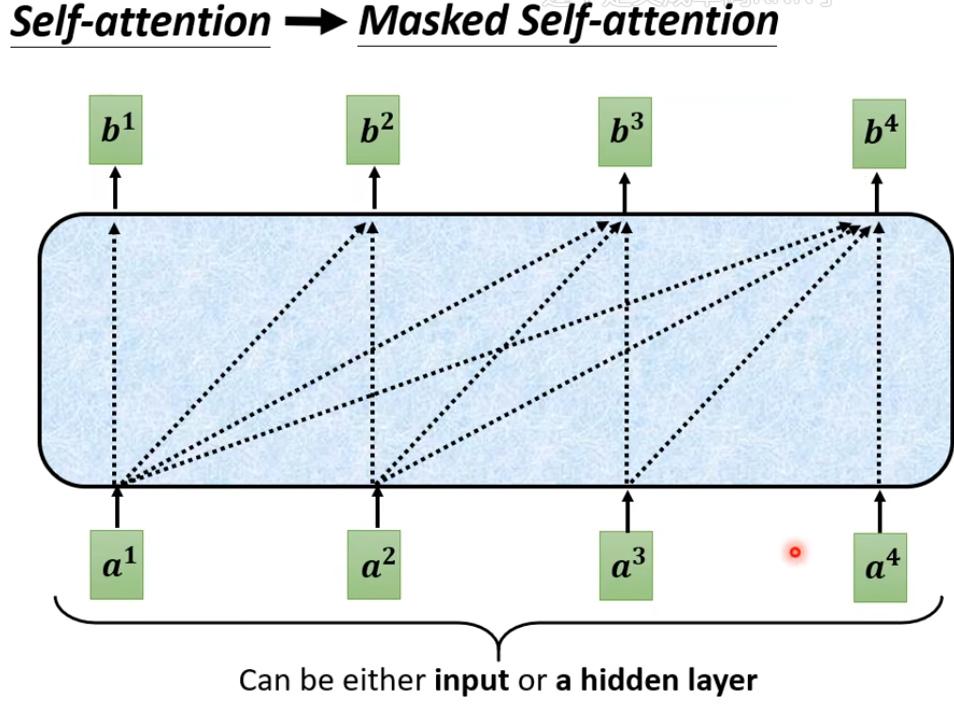
因为Decoder中是一个一个输出的,当前时刻并不会获得之后时刻的信息
ps:Encoder是根据全部信息训练出来的,那么Decoder这样做会不会“不对称” ?如果实时性要求不是特别高的话,那是不是可以设置一个窗口来让当前时刻学习一下窗口长度的之后时刻的信息?
为了让Decoder可以停下,还需要设置一个特殊符号EOS。
Non-Autoregressive (NAT)
一次产生所有词
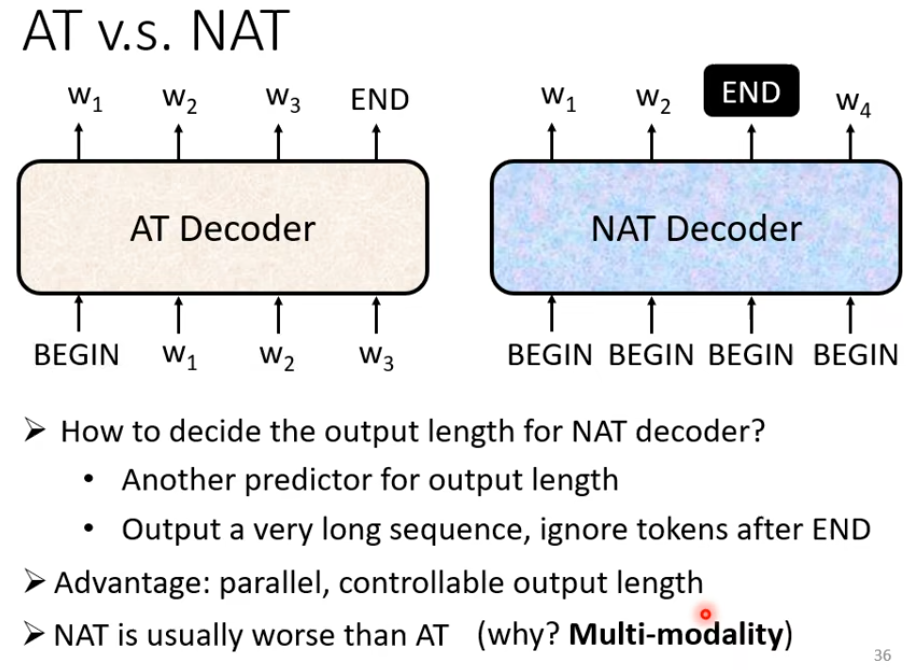
4. Encoder-Decoder之间的传递
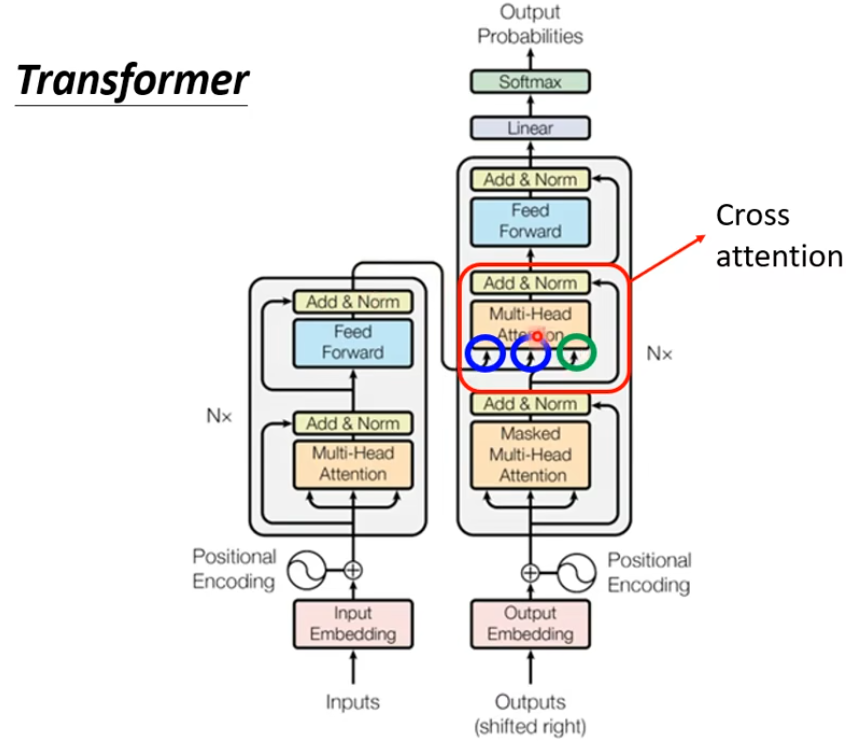
Decoder将输入进行Att后得到的结果当作Query,Encoder中的输出作为Key、Value进行计算
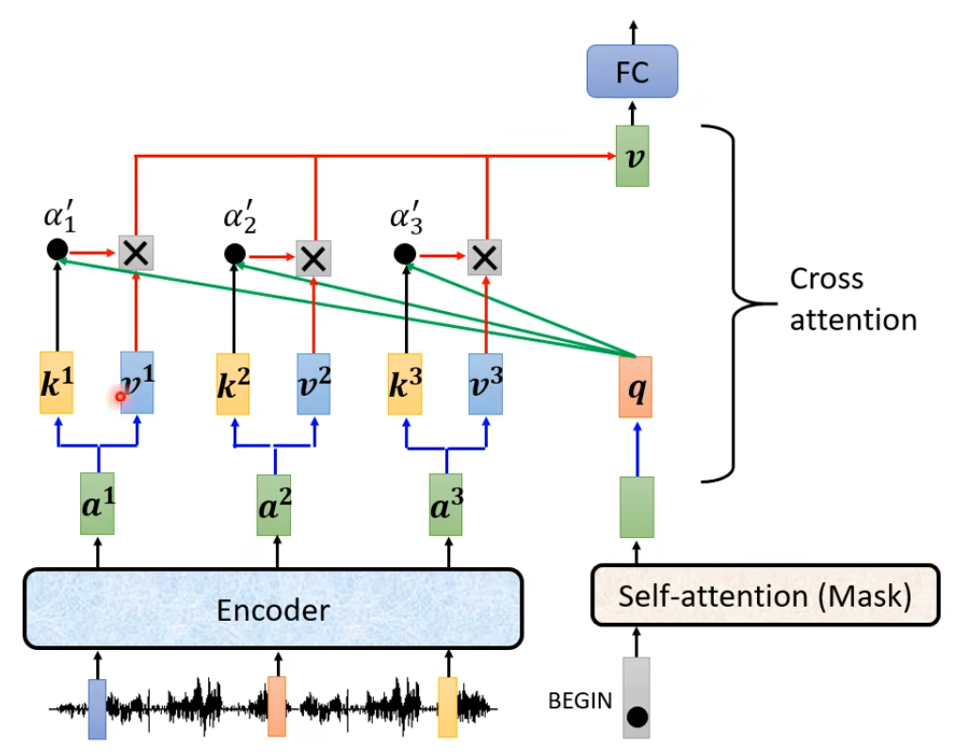
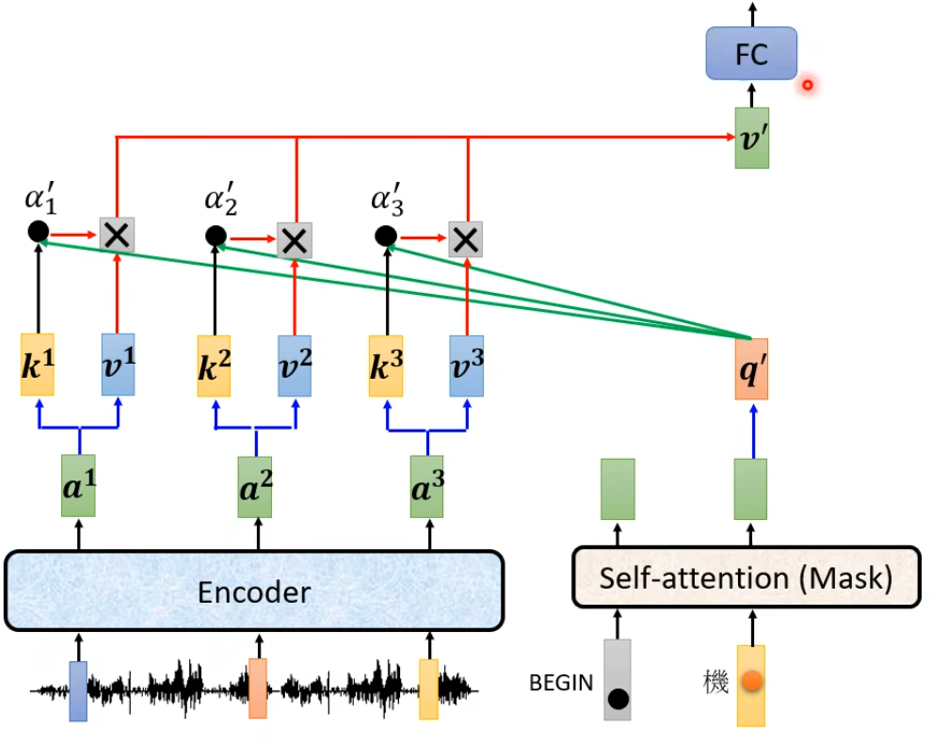
下面是使用seq2seq做语音识别的文章,使用到了Cross Att思想
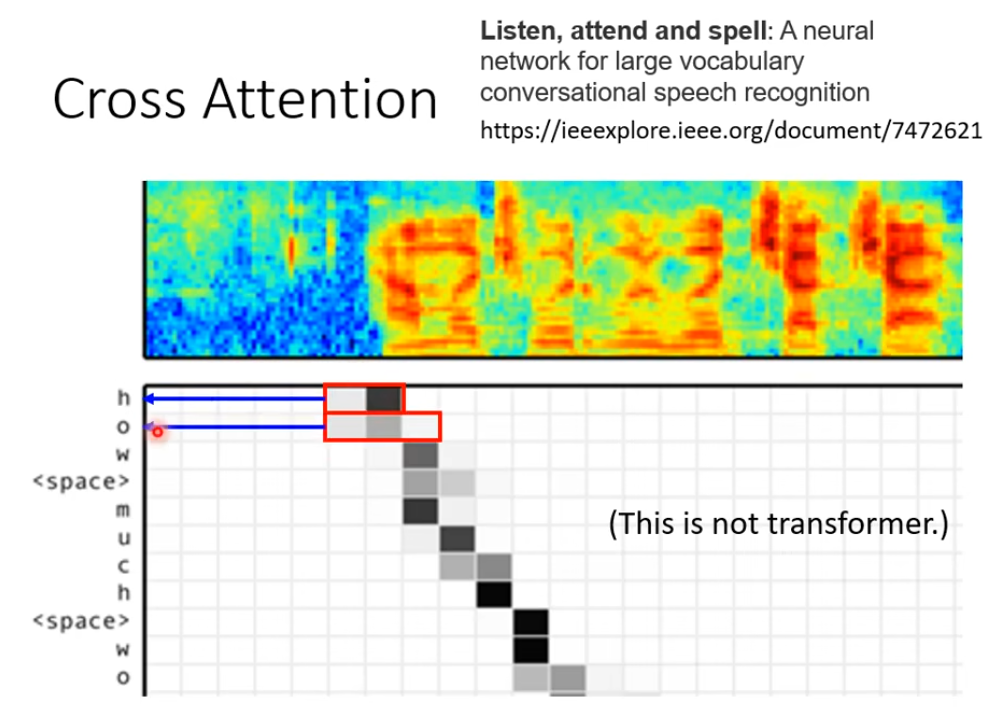
首先上面的声音列向量输入到Encoder中,然后decoder输出与Encoder输出做cross Att
5. Learn To more
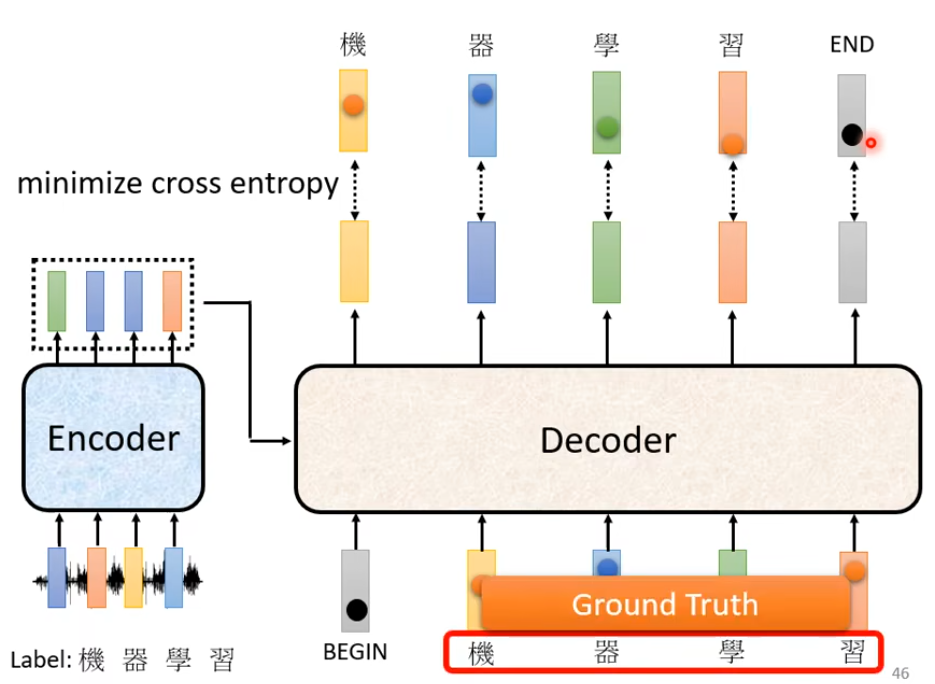
6. Training
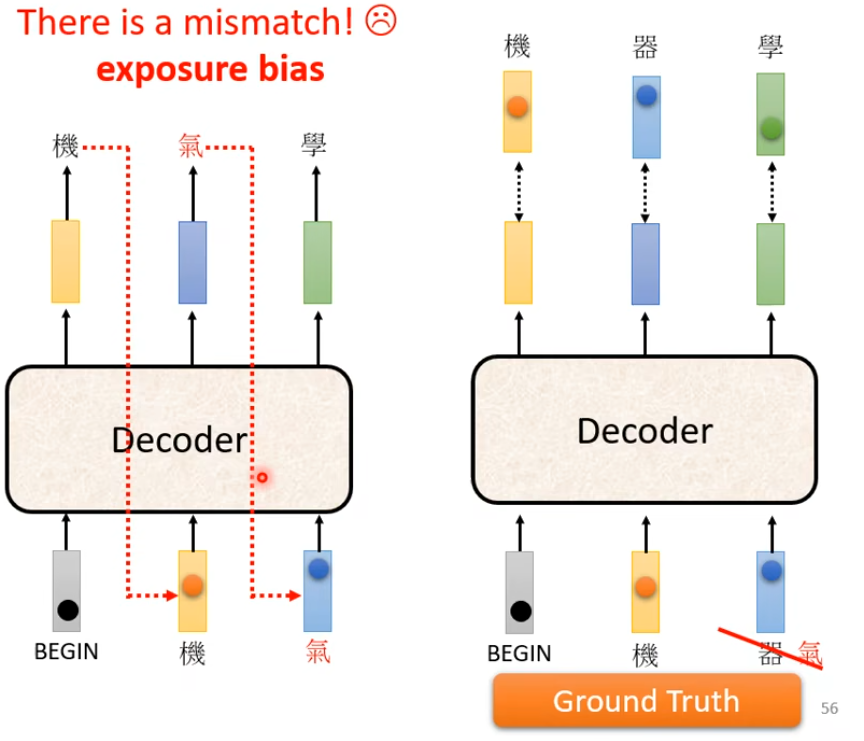
在训练的时候会给Decoder看正确答案,也就是告诉Decoder 输入BEGIN时候要输出机,输入机的时候要输出器 … …。 这种技术为Teacher Forcing
但是现在有个问题就是Decoder在训练过程中看到的是正确答案。真正在使用的过程中没有正确答案可以看,这其中存在一个Mismatch
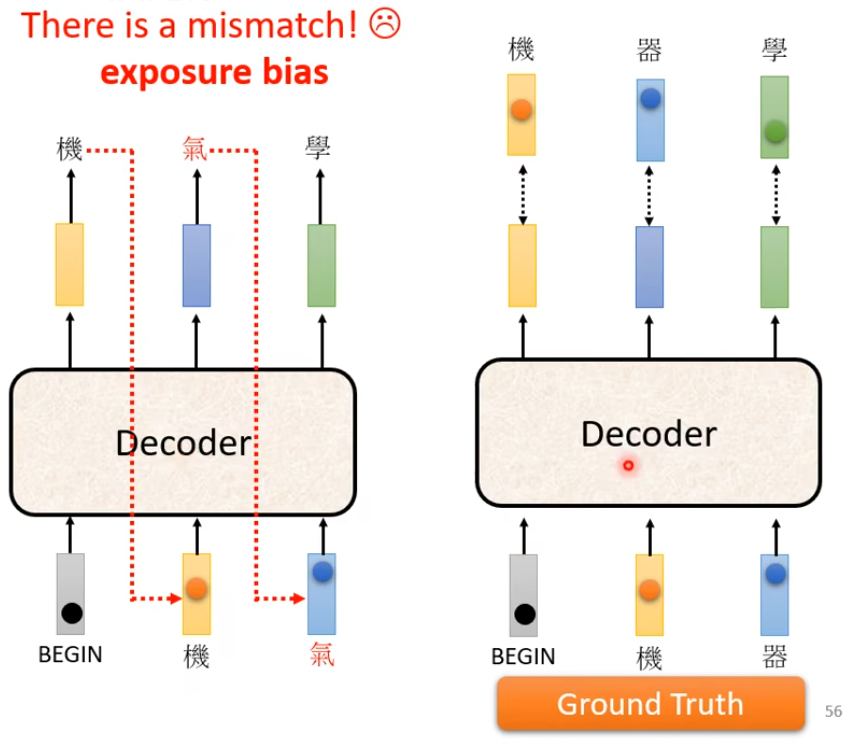
这就可能导致一步错 步步错的问题
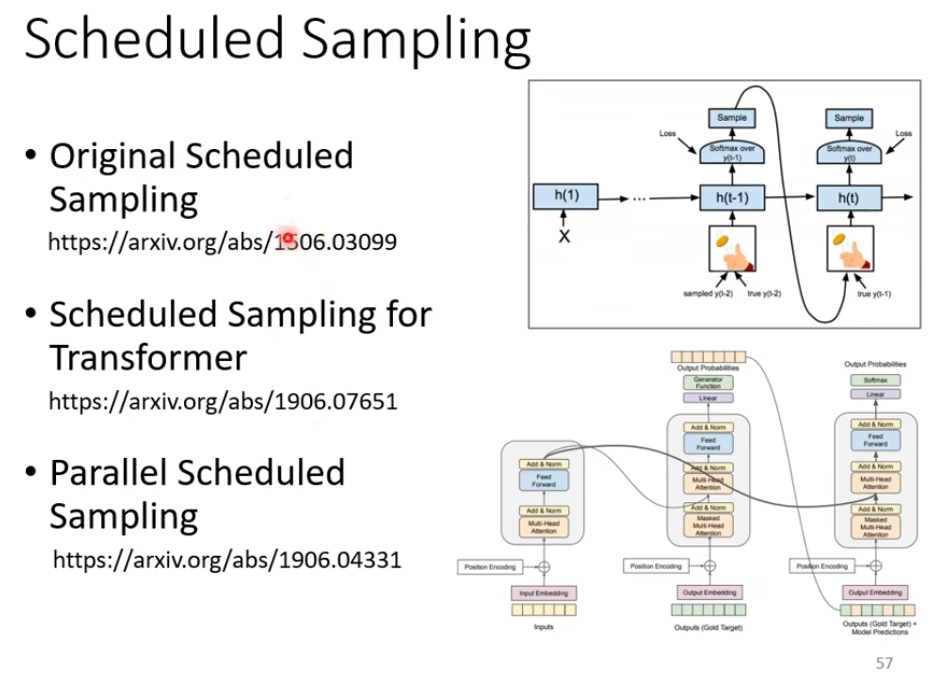
解决方法之一就是在训练过程中给Decoder加一些错误的标签,类似于加噪声,正则化
这种技术叫做 Scheduled Sampling
评估
在训练时后的损失是单个词汇的,而评估的时候是评估整个句子
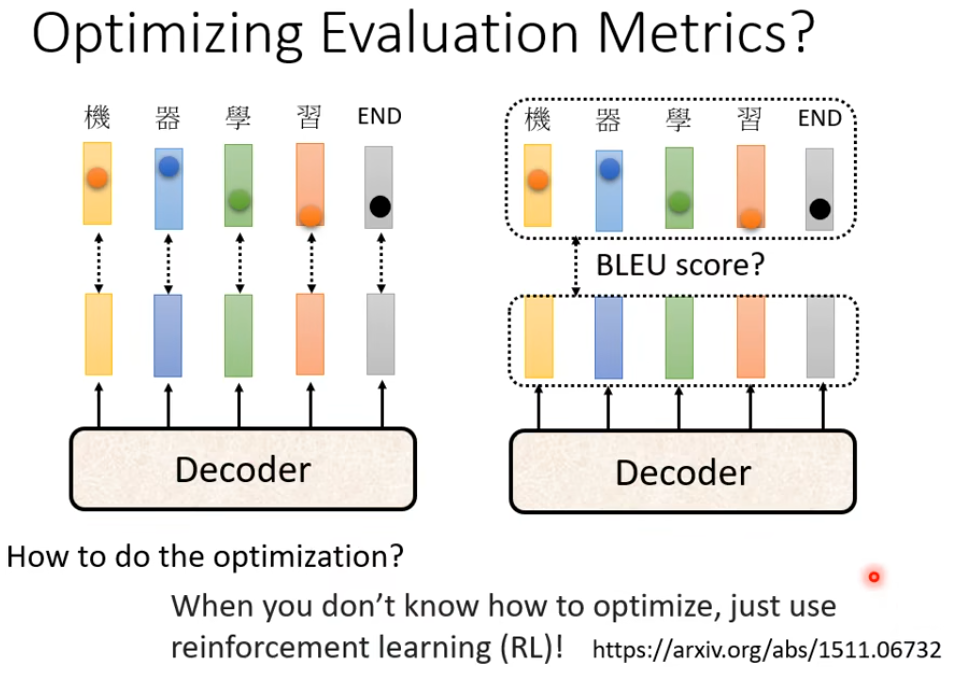
那能不能training的时候就考虑整个句子呢,即training的时候使用的就是BLEU loss呢? 可以,但是BLEU本身是很复杂,是不能微分的。
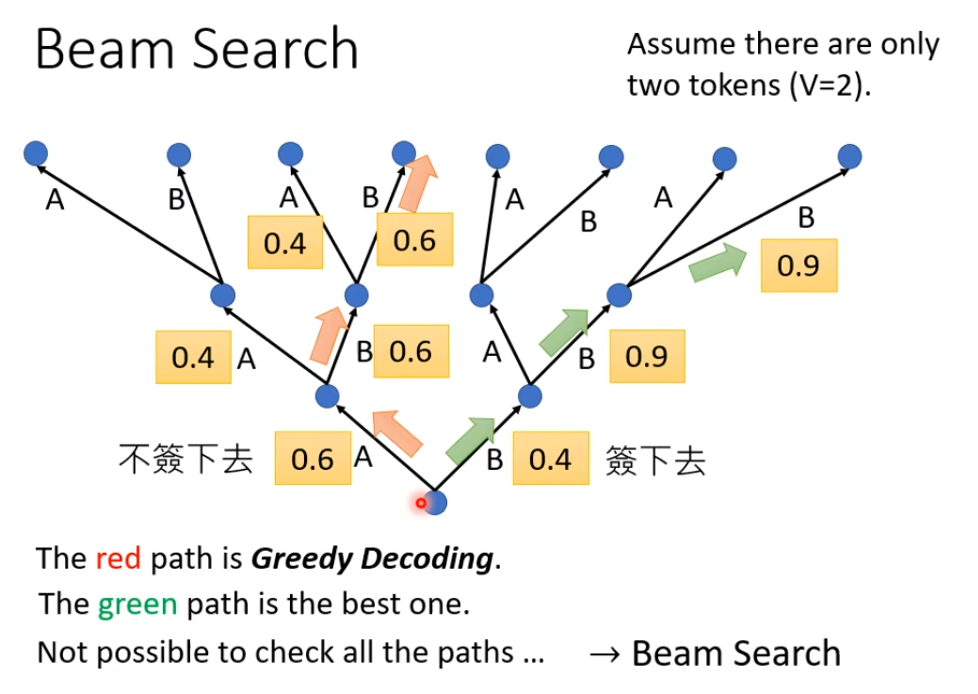
Trick
遇到无法 optimization的LOSS,用RL硬Train一发就对了,把它当作是RL的

Guided Attention
强迫机器把输入的每个东西都“看到”
To Learn more
自注意力与交叉注意力
交叉注意力
在交叉注意力中,每个输入序列都有自己的查询向量,而输出序列的每个位置都有一个键向量。当进行交叉注意力计算时,模型会根据查询向量和键向量之间的相似度来分配权重,从而决定要将哪些信息纳入到当前位置的计算中。
这种权重的分配过程可以被看做是对每个输入序列中的每个位置进行的关注度量,因此我们可以通过观察这些关注度量来理解模型在进行推断时关注了哪些输入位置,并进一步解释模型的决策原因。
此外,在交叉注意力中,我们还可以通过可视化注意力权重矩阵来进一步解释模型的决策原因,并理解哪些输入特征对于推断结果的产生起到了决定性的作用。
因此,交叉注意力在深度学习模型中具有较好的可解释性,可以帮助我们更好地理解模型的决策过程和推断结果。
交叉注意力为什么可以同时关注多个输入序列之间的依赖关系
交叉注意力可以同时关注多个输入序列之间的依赖关系的原因在于:
- 分别计算多个输入序列的查询向量,以及一个输出序列(假定要根据这些输入序列得到该输出序列),然后将多个查询向量联系在一起,以便同时考虑到所有输入序列与输出序列之间的关系。
- 在计算注意力权重时,会同时计算多个输入序列和输出序列之间的相似度,以便于获取每个输入序列的特征,然后将它们组合起来。
- 在每个时刻,交叉注意力都可以计算多个输入序列当前位置的特征向量,然后加权求和得到一个位置无关的向量表示。这个向量用于计算输出序列的下一个位置。
因此,交叉注意力通过对多个输入序列的特征进行编码以及计算它们与输出序列之间的相似度,可以同时关注多个输入序列之间的依赖关系,并且根据它们进行更好的推理和预测。它可以应用于一些需要对多个输入序列进行建模的任务,如机器翻译、图像描述等。
区别
https://machinelearningmastery.com/the-transformer-attention-mechanism/
自注意力机制和交叉注意力机制都是注意力机制,在深度学习中都被广泛应用于序列建模任务中,但它们之间也存在一些明显的区别。
- 输入的不同:自注意力机制仅关注单个输入序列的不同位置之间的依赖关系,而交叉注意力机制可以同时关注多个输入序列之间的依赖关系。
- 查询、键和值的不同:在自注意力机制中,查询、键和值都是从同一个输入序列中提取得到的,而在交叉注意力机制中,查询和值是从输出序列中提取得到的,键则是从另一个输入序列中提取得到的。
- 实现的不同:自注意力机制和交叉注意力机制在实现上也略有不同。在自注意力机制中,我们可以通过一个线性变换对输入序列进行映射,然后基于映射后得到的特征向量进行查询、键和值的计算。而在交叉注意力机制中,我们需要将不同的输入序列映射到同一维度上,然后进行类似的计算。
- 应用的不同:自注意力机制主要应用于单个输入序列的处理,可以用于语言建模、情感分析等任务。而交叉注意力机制则主要应用于关联不同的输入序列,可以用于机器翻译、图像描述等任务。
综上所述,自注意力和交叉注意力在输入、查询、键和值的不同、实现方式和应用场景的不同,因此在具体应用时需要酌情选择。
例子
1. 自注意力和交叉注意力 例子
- 自注意力机制的一个例子是Transformer架构中的编码器和解码器的每一层都有一个自注意力子层,它可以让模型学习到序列中每个位置与其他位置的关系。1
- 交叉注意力机制的一个例子是Transformer架构中的解码器的第二个子层,它可以让模型学习到目标序列与源序列之间的对齐关系。1
下面是一个自注意力机制和交叉注意力机制的图示:
1 | Self-attention: |
2. 交叉注意力多模态翻译
- 一个交叉注意力应用于多源机器翻译的例子是多模态机器翻译,它可以让模型同时使用图像和文本作为输入,生成目标语言的文本输出。1
- 一个交叉注意力应用于多模态融合的例子是视频分类,它可以让模型同时使用视觉和听觉信息作为输入,生成视频类别的输出。2
下面是一个多模态机器翻译的图示:
1 | Image: [x1, x2, ..., xn] (image features) |
其中,Image和Text是两个不同类型的输入序列,Encoder是一个编码器网络,Decoder是一个解码器网络,Cross-attention是一个交叉注意力机制,Attention是一个注意力函数,a11,a21,…ak(n+m)是注意力权重。3
注意力机制作用被高估了?苹果等机构新研究:把注意力矩阵替换成常数矩阵后,性能差异不大
【经典精读】Transformer模型和Attention机制
Pytorch中 nn.Transformer的使用详解与Transformer的黑盒讲解


